
Retrieval Augmented Generation using Langchain + MongoVDB
By:
Oswaldo Pineda
Mar 7, 2025
Retrieval Augmented Generation using Langchain + MongoVDB
By:
Oswaldo Pineda
Mar 7, 2025
Retrieval Augmented Generation using Langchain + MongoVDB
By:
Oswaldo Pineda
Mar 7, 2025
Retrieval Augmented Generation using Langchain + MongoVDB
By:
Oswaldo Pineda
Mar 7, 2025
Retrieval Augmented Generation using Langchain + MongoVDB
By:
Oswaldo Pineda
Mar 7, 2025
Retrieval Augmented Generation using Langchain + MongoVDB
Augmented retrieval or RAG is a technique that allows us to provide additional context to our conversions with a natural language model (LLM), this context can help us to generate more specific answers with knowledge that may be specific to our project and with which the model we are using has not been trained.
Example, we want to implement an assistant in our platform which can provide support to customers about a product or service, our assistant will only have the context with which he was trained, being our documentation about the product a resource which he can use to give a better answer about the problem to solve, automatically generating searches to our database whenever necessary.
First of all, let's review some key concepts to facilitate the understanding of the code.
What is Langchain?
Langchain is a Python framework with tools for communicating with LLMs to facilitate basic interactions with the different models, this allows us with just a few lines of code to connect to a wide variety of available models and perform tasks such as having converts, creating agents, configuring tasks, or using embeddings to process text, something that will be useful for configuring our RAG.
What is VectorDB
A vector database is a list of numbers where each element of the list represents a characteristic or attribute of the data, these values are assigned by the embedding with which it is created and the value can vary from one embedding to another depending on how optimized it is to describe certain attributes, some being more focused on describing characteristics such as colors, tones or size.
This looks as follows
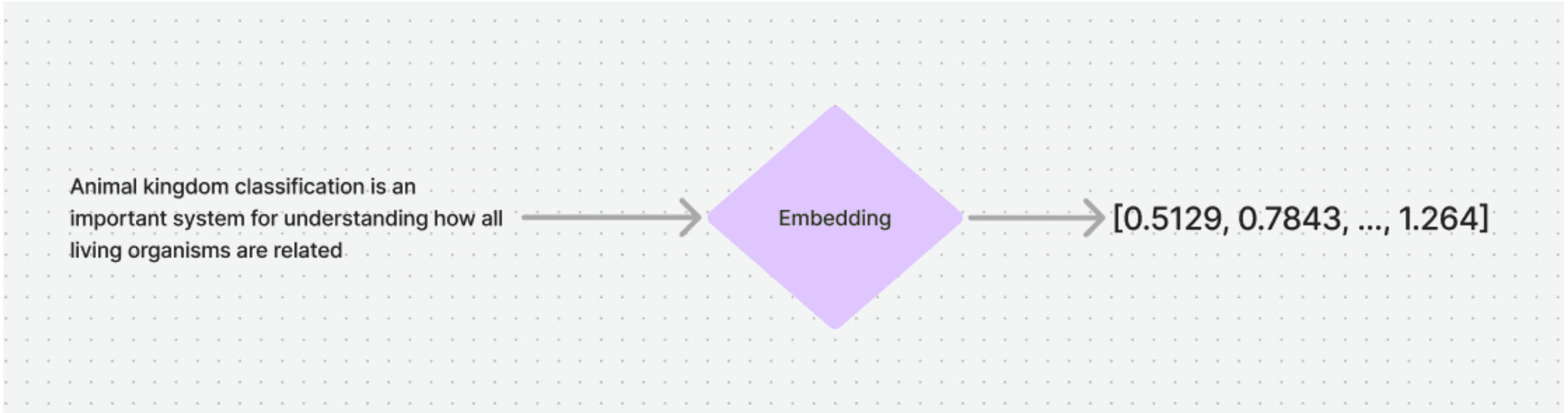
Being this array of numerical values the field to be stored in our vector database, with which our search engine will apply a proximity algorithm to get the most relevant records with respect to a search.
Let's check the python implementation
First of all we have to create a collection in Mongo in which we will be storing our documents as we do with any kind of record. In this example we will create a base class to handle interactions with the data either store or consume.
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[<collection_name>]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)Once the collection is configured, we will have to configure an index through Atlas Search either in the Cloud mongo platform itself or by writing some code. Create your index model, then create the search index.
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)Once our Mongo configuration is finished, we can connect our embedding that will allow us to have text chunks and assign a score to each one to later perform our search, in this example we will use the OpenAI embedding.
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)Now we have to load the content of our file using a loader that will allow us with just one line to create documents of the size assigned in our embedding, in this case multiple text chunks of 1000 tokens.
Our documents can include metadata which will help us later to have a limited scope of data to rank which is very useful for separating data into groups such as documents by project or user.
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []This will result in a document with the following structure.

In which we will have to save in MongoDb in our previously created collection and this will add our record to our Index automatically.
def save_embeddings(self, data):
return self.collection.insert_many(data)Finally, the only thing left to do is to start consuming data.
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)But we can modify our retriever based on different params according to our needs.
# Retrieve more documents with higher diversity
# Useful if your dataset has many similar documents
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 6, 'lambda_mult': 0.25}
)
# Fetch more documents for the MMR algorithm to consider
# But only return the top 5
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 5, 'fetch_k': 50}
)
# Only retrieve documents that have a relevance score
# Above a certain threshold
self.vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.8}
)
# Only get the single most similar document from the dataset
self.vector_store.as_retriever(search_kwargs={'k': 1})
# Use a filter to only retrieve documents from a specific paper
self.vector_store.as_retriever(
search_kwargs={'filter': {'paper_title':'GPT-4 Technical Report'}}Some common integrations are:
Provide context about a product to improve customer service.
Create a chat to talk with a model about a local document.
Business analysis and decision-making.
Resources:
https://www.mongodb.com/resources/basics/databases/vector-databases?msockid=1ff5be6fd99d6b2405faaa3fd8e46a6a
https://python.langchain.com/api_reference/core/vectorstores/langchain_core.vectorstores.base.VectorStore.html#langchai
Final code:
import os
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
from pymongo.operations import SearchIndexModel
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from datetime import datetime
MONGO_USER = os.getenv("MONGO_USER", "teamx")
MONGO_PASSWORD = os.getenv("MONGO_PASSWORD", "lPoIoKOFavVJBPJy")
MONGO_SPACE = os.getenv("MONGO_SPACE", "personax")
MONGO_DB_NAME = os.getenv("MONGO_DB_NAME", "personax-dev")
EMBEDDINGS_COLLECTION = os.getenv("EMBEDDINGS_COLLECTION", "data_embeddings_test")
ATLAS_VECTOR_SEARCH_INDEX_NAME = os.getenv(
"ATLAS_VECTOR_SEARCH_INDEX_NAME", "vector_index_dev_test"
)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
OPENAI_MODEL_NAME = os.getenv("OPENAI_MODEL_NAME", "gpt-4o")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "text-embedding-3-small")
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[EMBEDDINGS_COLLECTION]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)
def save_embeddings(self, data):
return self.collection.insert_many(data)
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []
if __name__ == "__main__":
file_to_ingest = "./real-state-data.pdf"
rag = BaseRAG()
# rag.create_index("example_index_name")
# rag.ingest_file(file_to_ingest, {"category": "real-state"})
query = "What is the..."
result = rag.retrieve(query)
print(result)Retrieval Augmented Generation using Langchain + MongoVDB
Augmented retrieval or RAG is a technique that allows us to provide additional context to our conversions with a natural language model (LLM), this context can help us to generate more specific answers with knowledge that may be specific to our project and with which the model we are using has not been trained.
Example, we want to implement an assistant in our platform which can provide support to customers about a product or service, our assistant will only have the context with which he was trained, being our documentation about the product a resource which he can use to give a better answer about the problem to solve, automatically generating searches to our database whenever necessary.
First of all, let's review some key concepts to facilitate the understanding of the code.
What is Langchain?
Langchain is a Python framework with tools for communicating with LLMs to facilitate basic interactions with the different models, this allows us with just a few lines of code to connect to a wide variety of available models and perform tasks such as having converts, creating agents, configuring tasks, or using embeddings to process text, something that will be useful for configuring our RAG.
What is VectorDB
A vector database is a list of numbers where each element of the list represents a characteristic or attribute of the data, these values are assigned by the embedding with which it is created and the value can vary from one embedding to another depending on how optimized it is to describe certain attributes, some being more focused on describing characteristics such as colors, tones or size.
This looks as follows
Being this array of numerical values the field to be stored in our vector database, with which our search engine will apply a proximity algorithm to get the most relevant records with respect to a search.
Let's check the python implementation
First of all we have to create a collection in Mongo in which we will be storing our documents as we do with any kind of record. In this example we will create a base class to handle interactions with the data either store or consume.
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[<collection_name>]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)Once the collection is configured, we will have to configure an index through Atlas Search either in the Cloud mongo platform itself or by writing some code. Create your index model, then create the search index.
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)Once our Mongo configuration is finished, we can connect our embedding that will allow us to have text chunks and assign a score to each one to later perform our search, in this example we will use the OpenAI embedding.
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)Now we have to load the content of our file using a loader that will allow us with just one line to create documents of the size assigned in our embedding, in this case multiple text chunks of 1000 tokens.
Our documents can include metadata which will help us later to have a limited scope of data to rank which is very useful for separating data into groups such as documents by project or user.
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []This will result in a document with the following structure.
In which we will have to save in MongoDb in our previously created collection and this will add our record to our Index automatically.
def save_embeddings(self, data):
return self.collection.insert_many(data)Finally, the only thing left to do is to start consuming data.
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)But we can modify our retriever based on different params according to our needs.
# Retrieve more documents with higher diversity
# Useful if your dataset has many similar documents
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 6, 'lambda_mult': 0.25}
)
# Fetch more documents for the MMR algorithm to consider
# But only return the top 5
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 5, 'fetch_k': 50}
)
# Only retrieve documents that have a relevance score
# Above a certain threshold
self.vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.8}
)
# Only get the single most similar document from the dataset
self.vector_store.as_retriever(search_kwargs={'k': 1})
# Use a filter to only retrieve documents from a specific paper
self.vector_store.as_retriever(
search_kwargs={'filter': {'paper_title':'GPT-4 Technical Report'}}Some common integrations are:
Provide context about a product to improve customer service.
Create a chat to talk with a model about a local document.
Business analysis and decision-making.
Resources:
https://www.mongodb.com/resources/basics/databases/vector-databases?msockid=1ff5be6fd99d6b2405faaa3fd8e46a6a
https://python.langchain.com/api_reference/core/vectorstores/langchain_core.vectorstores.base.VectorStore.html#langchai
Final code:
import os
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
from pymongo.operations import SearchIndexModel
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from datetime import datetime
MONGO_USER = os.getenv("MONGO_USER", "teamx")
MONGO_PASSWORD = os.getenv("MONGO_PASSWORD", "lPoIoKOFavVJBPJy")
MONGO_SPACE = os.getenv("MONGO_SPACE", "personax")
MONGO_DB_NAME = os.getenv("MONGO_DB_NAME", "personax-dev")
EMBEDDINGS_COLLECTION = os.getenv("EMBEDDINGS_COLLECTION", "data_embeddings_test")
ATLAS_VECTOR_SEARCH_INDEX_NAME = os.getenv(
"ATLAS_VECTOR_SEARCH_INDEX_NAME", "vector_index_dev_test"
)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
OPENAI_MODEL_NAME = os.getenv("OPENAI_MODEL_NAME", "gpt-4o")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "text-embedding-3-small")
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[EMBEDDINGS_COLLECTION]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)
def save_embeddings(self, data):
return self.collection.insert_many(data)
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []
if __name__ == "__main__":
file_to_ingest = "./real-state-data.pdf"
rag = BaseRAG()
# rag.create_index("example_index_name")
# rag.ingest_file(file_to_ingest, {"category": "real-state"})
query = "What is the..."
result = rag.retrieve(query)
print(result)Retrieval Augmented Generation using Langchain + MongoVDB
Augmented retrieval or RAG is a technique that allows us to provide additional context to our conversions with a natural language model (LLM), this context can help us to generate more specific answers with knowledge that may be specific to our project and with which the model we are using has not been trained.
Example, we want to implement an assistant in our platform which can provide support to customers about a product or service, our assistant will only have the context with which he was trained, being our documentation about the product a resource which he can use to give a better answer about the problem to solve, automatically generating searches to our database whenever necessary.
First of all, let's review some key concepts to facilitate the understanding of the code.
What is Langchain?
Langchain is a Python framework with tools for communicating with LLMs to facilitate basic interactions with the different models, this allows us with just a few lines of code to connect to a wide variety of available models and perform tasks such as having converts, creating agents, configuring tasks, or using embeddings to process text, something that will be useful for configuring our RAG.
What is VectorDB
A vector database is a list of numbers where each element of the list represents a characteristic or attribute of the data, these values are assigned by the embedding with which it is created and the value can vary from one embedding to another depending on how optimized it is to describe certain attributes, some being more focused on describing characteristics such as colors, tones or size.
This looks as follows
Being this array of numerical values the field to be stored in our vector database, with which our search engine will apply a proximity algorithm to get the most relevant records with respect to a search.
Let's check the python implementation
First of all we have to create a collection in Mongo in which we will be storing our documents as we do with any kind of record. In this example we will create a base class to handle interactions with the data either store or consume.
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[<collection_name>]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)Once the collection is configured, we will have to configure an index through Atlas Search either in the Cloud mongo platform itself or by writing some code. Create your index model, then create the search index.
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)Once our Mongo configuration is finished, we can connect our embedding that will allow us to have text chunks and assign a score to each one to later perform our search, in this example we will use the OpenAI embedding.
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)Now we have to load the content of our file using a loader that will allow us with just one line to create documents of the size assigned in our embedding, in this case multiple text chunks of 1000 tokens.
Our documents can include metadata which will help us later to have a limited scope of data to rank which is very useful for separating data into groups such as documents by project or user.
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []This will result in a document with the following structure.
In which we will have to save in MongoDb in our previously created collection and this will add our record to our Index automatically.
def save_embeddings(self, data):
return self.collection.insert_many(data)Finally, the only thing left to do is to start consuming data.
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)But we can modify our retriever based on different params according to our needs.
# Retrieve more documents with higher diversity
# Useful if your dataset has many similar documents
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 6, 'lambda_mult': 0.25}
)
# Fetch more documents for the MMR algorithm to consider
# But only return the top 5
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 5, 'fetch_k': 50}
)
# Only retrieve documents that have a relevance score
# Above a certain threshold
self.vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.8}
)
# Only get the single most similar document from the dataset
self.vector_store.as_retriever(search_kwargs={'k': 1})
# Use a filter to only retrieve documents from a specific paper
self.vector_store.as_retriever(
search_kwargs={'filter': {'paper_title':'GPT-4 Technical Report'}}Some common integrations are:
Provide context about a product to improve customer service.
Create a chat to talk with a model about a local document.
Business analysis and decision-making.
Resources:
https://www.mongodb.com/resources/basics/databases/vector-databases?msockid=1ff5be6fd99d6b2405faaa3fd8e46a6a
https://python.langchain.com/api_reference/core/vectorstores/langchain_core.vectorstores.base.VectorStore.html#langchai
Final code:
import os
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
from pymongo.operations import SearchIndexModel
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from datetime import datetime
MONGO_USER = os.getenv("MONGO_USER", "teamx")
MONGO_PASSWORD = os.getenv("MONGO_PASSWORD", "lPoIoKOFavVJBPJy")
MONGO_SPACE = os.getenv("MONGO_SPACE", "personax")
MONGO_DB_NAME = os.getenv("MONGO_DB_NAME", "personax-dev")
EMBEDDINGS_COLLECTION = os.getenv("EMBEDDINGS_COLLECTION", "data_embeddings_test")
ATLAS_VECTOR_SEARCH_INDEX_NAME = os.getenv(
"ATLAS_VECTOR_SEARCH_INDEX_NAME", "vector_index_dev_test"
)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
OPENAI_MODEL_NAME = os.getenv("OPENAI_MODEL_NAME", "gpt-4o")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "text-embedding-3-small")
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[EMBEDDINGS_COLLECTION]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)
def save_embeddings(self, data):
return self.collection.insert_many(data)
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []
if __name__ == "__main__":
file_to_ingest = "./real-state-data.pdf"
rag = BaseRAG()
# rag.create_index("example_index_name")
# rag.ingest_file(file_to_ingest, {"category": "real-state"})
query = "What is the..."
result = rag.retrieve(query)
print(result)Retrieval Augmented Generation using Langchain + MongoVDB
Augmented retrieval or RAG is a technique that allows us to provide additional context to our conversions with a natural language model (LLM), this context can help us to generate more specific answers with knowledge that may be specific to our project and with which the model we are using has not been trained.
Example, we want to implement an assistant in our platform which can provide support to customers about a product or service, our assistant will only have the context with which he was trained, being our documentation about the product a resource which he can use to give a better answer about the problem to solve, automatically generating searches to our database whenever necessary.
First of all, let's review some key concepts to facilitate the understanding of the code.
What is Langchain?
Langchain is a Python framework with tools for communicating with LLMs to facilitate basic interactions with the different models, this allows us with just a few lines of code to connect to a wide variety of available models and perform tasks such as having converts, creating agents, configuring tasks, or using embeddings to process text, something that will be useful for configuring our RAG.
What is VectorDB
A vector database is a list of numbers where each element of the list represents a characteristic or attribute of the data, these values are assigned by the embedding with which it is created and the value can vary from one embedding to another depending on how optimized it is to describe certain attributes, some being more focused on describing characteristics such as colors, tones or size.
This looks as follows
Being this array of numerical values the field to be stored in our vector database, with which our search engine will apply a proximity algorithm to get the most relevant records with respect to a search.
Let's check the python implementation
First of all we have to create a collection in Mongo in which we will be storing our documents as we do with any kind of record. In this example we will create a base class to handle interactions with the data either store or consume.
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[<collection_name>]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)Once the collection is configured, we will have to configure an index through Atlas Search either in the Cloud mongo platform itself or by writing some code. Create your index model, then create the search index.
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)Once our Mongo configuration is finished, we can connect our embedding that will allow us to have text chunks and assign a score to each one to later perform our search, in this example we will use the OpenAI embedding.
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)Now we have to load the content of our file using a loader that will allow us with just one line to create documents of the size assigned in our embedding, in this case multiple text chunks of 1000 tokens.
Our documents can include metadata which will help us later to have a limited scope of data to rank which is very useful for separating data into groups such as documents by project or user.
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []This will result in a document with the following structure.
In which we will have to save in MongoDb in our previously created collection and this will add our record to our Index automatically.
def save_embeddings(self, data):
return self.collection.insert_many(data)Finally, the only thing left to do is to start consuming data.
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)But we can modify our retriever based on different params according to our needs.
# Retrieve more documents with higher diversity
# Useful if your dataset has many similar documents
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 6, 'lambda_mult': 0.25}
)
# Fetch more documents for the MMR algorithm to consider
# But only return the top 5
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 5, 'fetch_k': 50}
)
# Only retrieve documents that have a relevance score
# Above a certain threshold
self.vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.8}
)
# Only get the single most similar document from the dataset
self.vector_store.as_retriever(search_kwargs={'k': 1})
# Use a filter to only retrieve documents from a specific paper
self.vector_store.as_retriever(
search_kwargs={'filter': {'paper_title':'GPT-4 Technical Report'}}Some common integrations are:
Provide context about a product to improve customer service.
Create a chat to talk with a model about a local document.
Business analysis and decision-making.
Resources:
https://www.mongodb.com/resources/basics/databases/vector-databases?msockid=1ff5be6fd99d6b2405faaa3fd8e46a6a
https://python.langchain.com/api_reference/core/vectorstores/langchain_core.vectorstores.base.VectorStore.html#langchai
Final code:
import os
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
from pymongo.operations import SearchIndexModel
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from datetime import datetime
MONGO_USER = os.getenv("MONGO_USER", "teamx")
MONGO_PASSWORD = os.getenv("MONGO_PASSWORD", "lPoIoKOFavVJBPJy")
MONGO_SPACE = os.getenv("MONGO_SPACE", "personax")
MONGO_DB_NAME = os.getenv("MONGO_DB_NAME", "personax-dev")
EMBEDDINGS_COLLECTION = os.getenv("EMBEDDINGS_COLLECTION", "data_embeddings_test")
ATLAS_VECTOR_SEARCH_INDEX_NAME = os.getenv(
"ATLAS_VECTOR_SEARCH_INDEX_NAME", "vector_index_dev_test"
)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
OPENAI_MODEL_NAME = os.getenv("OPENAI_MODEL_NAME", "gpt-4o")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "text-embedding-3-small")
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[EMBEDDINGS_COLLECTION]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)
def save_embeddings(self, data):
return self.collection.insert_many(data)
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []
if __name__ == "__main__":
file_to_ingest = "./real-state-data.pdf"
rag = BaseRAG()
# rag.create_index("example_index_name")
# rag.ingest_file(file_to_ingest, {"category": "real-state"})
query = "What is the..."
result = rag.retrieve(query)
print(result)Retrieval Augmented Generation using Langchain + MongoVDB
Augmented retrieval or RAG is a technique that allows us to provide additional context to our conversions with a natural language model (LLM), this context can help us to generate more specific answers with knowledge that may be specific to our project and with which the model we are using has not been trained.
Example, we want to implement an assistant in our platform which can provide support to customers about a product or service, our assistant will only have the context with which he was trained, being our documentation about the product a resource which he can use to give a better answer about the problem to solve, automatically generating searches to our database whenever necessary.
First of all, let's review some key concepts to facilitate the understanding of the code.
What is Langchain?
Langchain is a Python framework with tools for communicating with LLMs to facilitate basic interactions with the different models, this allows us with just a few lines of code to connect to a wide variety of available models and perform tasks such as having converts, creating agents, configuring tasks, or using embeddings to process text, something that will be useful for configuring our RAG.
What is VectorDB
A vector database is a list of numbers where each element of the list represents a characteristic or attribute of the data, these values are assigned by the embedding with which it is created and the value can vary from one embedding to another depending on how optimized it is to describe certain attributes, some being more focused on describing characteristics such as colors, tones or size.
This looks as follows
Being this array of numerical values the field to be stored in our vector database, with which our search engine will apply a proximity algorithm to get the most relevant records with respect to a search.
Let's check the python implementation
First of all we have to create a collection in Mongo in which we will be storing our documents as we do with any kind of record. In this example we will create a base class to handle interactions with the data either store or consume.
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[<collection_name>]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)Once the collection is configured, we will have to configure an index through Atlas Search either in the Cloud mongo platform itself or by writing some code. Create your index model, then create the search index.
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)Once our Mongo configuration is finished, we can connect our embedding that will allow us to have text chunks and assign a score to each one to later perform our search, in this example we will use the OpenAI embedding.
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)Now we have to load the content of our file using a loader that will allow us with just one line to create documents of the size assigned in our embedding, in this case multiple text chunks of 1000 tokens.
Our documents can include metadata which will help us later to have a limited scope of data to rank which is very useful for separating data into groups such as documents by project or user.
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []This will result in a document with the following structure.
In which we will have to save in MongoDb in our previously created collection and this will add our record to our Index automatically.
def save_embeddings(self, data):
return self.collection.insert_many(data)Finally, the only thing left to do is to start consuming data.
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)But we can modify our retriever based on different params according to our needs.
# Retrieve more documents with higher diversity
# Useful if your dataset has many similar documents
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 6, 'lambda_mult': 0.25}
)
# Fetch more documents for the MMR algorithm to consider
# But only return the top 5
self.vector_store.as_retriever(
search_type="mmr",
search_kwargs={'k': 5, 'fetch_k': 50}
)
# Only retrieve documents that have a relevance score
# Above a certain threshold
self.vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.8}
)
# Only get the single most similar document from the dataset
self.vector_store.as_retriever(search_kwargs={'k': 1})
# Use a filter to only retrieve documents from a specific paper
self.vector_store.as_retriever(
search_kwargs={'filter': {'paper_title':'GPT-4 Technical Report'}}Some common integrations are:
Provide context about a product to improve customer service.
Create a chat to talk with a model about a local document.
Business analysis and decision-making.
Resources:
https://www.mongodb.com/resources/basics/databases/vector-databases?msockid=1ff5be6fd99d6b2405faaa3fd8e46a6a
https://python.langchain.com/api_reference/core/vectorstores/langchain_core.vectorstores.base.VectorStore.html#langchai
Final code:
import os
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
from pymongo.operations import SearchIndexModel
from langchain.vectorstores import MongoDBAtlasVectorSearch
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from datetime import datetime
MONGO_USER = os.getenv("MONGO_USER", "teamx")
MONGO_PASSWORD = os.getenv("MONGO_PASSWORD", "lPoIoKOFavVJBPJy")
MONGO_SPACE = os.getenv("MONGO_SPACE", "personax")
MONGO_DB_NAME = os.getenv("MONGO_DB_NAME", "personax-dev")
EMBEDDINGS_COLLECTION = os.getenv("EMBEDDINGS_COLLECTION", "data_embeddings_test")
ATLAS_VECTOR_SEARCH_INDEX_NAME = os.getenv(
"ATLAS_VECTOR_SEARCH_INDEX_NAME", "vector_index_dev_test"
)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
OPENAI_MODEL_NAME = os.getenv("OPENAI_MODEL_NAME", "gpt-4o")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "text-embedding-3-small")
embedding = OpenAIEmbeddings(model=EMBEDDING_MODEL, chunk_size=1000)
class BaseRAG:
embedding = embedding
mongo_uri = (
f"mongodb+srv://{MONGO_USER}:{MONGO_PASSWORD}@{MONGO_SPACE}.yng1j.mongodb.net"
)
mongo_client = MongoClient(
mongo_uri,
server_api=ServerApi("1"),
maxPoolSize=50,
)
def __init__(self) -> None:
self.db = self.mongo_client[MONGO_DB_NAME]
self.collection = self.db[EMBEDDINGS_COLLECTION]
self.vector_store = MongoDBAtlasVectorSearch(
collection=self.collection,
embedding=embedding,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)
def create_index(self, index_name):
search_index_model = SearchIndexModel(
definition={
"fields": [
{
"numDimensions": 1536,
"path": "embedding",
"similarity": "cosine",
"type": "vector",
},
{"type": "filter", "path": "metadata.category"},
]
},
name=index_name,
type="vectorSearch",
)
return self.collection.create_search_index(model=search_index_model)
def save_embeddings(self, data):
return self.collection.insert_many(data)
def retrieve(self, query):
results = self.vector_store.similarity_search(
query, k=100, pre_filter={"category": "real-state"}
)
if not results:
print("No matches found on documents")
return ""
print(f"Retrieve results from {len(results)} documents")
return "\n\n".join(chunk.page_content for chunk in results)
def get_embedding(self, data):
return self.embedding.embed_query(data)
def prepare_documents(self, documents, metadata={}):
return [
{
"metadata": {
**doc.metadata,
**metadata,
"created_at": datetime.utcnow(),
},
"text": doc.page_content,
"embedding": self.get_embedding(doc.page_content),
}
for doc in documents
]
def ingest_file(self, file_path, metadata={}):
try:
file_content = PyPDFLoader(file_path=file_path).load()
if not file_content:
return []
docs = self.prepare_documents(file_content, metadata)
return self.save_embeddings(docs)
except Exception as e:
print(f"Error loading file: {e}")
return []
if __name__ == "__main__":
file_to_ingest = "./real-state-data.pdf"
rag = BaseRAG()
# rag.create_index("example_index_name")
# rag.ingest_file(file_to_ingest, {"category": "real-state"})
query = "What is the..."
result = rag.retrieve(query)
print(result)Explore other blog posts
Explore other blog posts